The test statistic used for detection is a special case of a function
of random variables. Testing the hypothesis  using the statistics
S is a standard statistical procedure. Important examples of the
test statistics are signal variances
using the statistics
S is a standard statistical procedure. Important examples of the
test statistics are signal variances
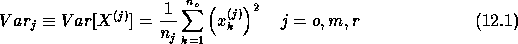
For white noise (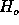 is true), the distribution of
is true), the distribution of  is a
is a
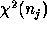 distribution. It is remarkable that, then,
distribution. It is remarkable that, then, 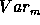 and
and
 are statistically independent. Note further the inequality
are statistically independent. Note further the inequality
 which is due to the extra variance,
which is due to the extra variance,
 , in the model signal with respect to the variance,
, in the model signal with respect to the variance, 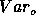 , of
the observations. The equality in these relations holds for pure
noise.
, of
the observations. The equality in these relations holds for pure
noise.
The larger the variance of the model series 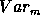 compared to the
residual variance
compared to the
residual variance 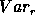 is, the more significant is the detection or
the better is the current parameter estimate, for problems (1) and (2)
respectively (Sect.
is, the more significant is the detection or
the better is the current parameter estimate, for problems (1) and (2)
respectively (Sect. ![]() ). Usually, the test statistics S in
TSA measure a ratio of two variances. They differ according to the
models assumed and the combination of the variances chosen. Since
models depend on frequency
). Usually, the test statistics S in
TSA measure a ratio of two variances. They differ according to the
models assumed and the combination of the variances chosen. Since
models depend on frequency  (or time lag l), so do the
variances
(or time lag l), so do the
variances  and
and 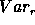 and test statistics S.
and test statistics S.
The statistics we recommend for use in the frequency domain are the
ones introduced by Scargle and the Analysis of Variance (AOV)
statistics. These methods are implemented in MIDAS commands
SCARGLE/TSA and AOV/TSA (Sect. ![]() ), respectively.
The Scargle statistic uses a pure sine model, the AOV statistic uses a
step function (phase binning). In the time domain, we recommend to
use the
), respectively.
The Scargle statistic uses a pure sine model, the AOV statistic uses a
step function (phase binning). In the time domain, we recommend to
use the  statistic with the COVAR/TSA and
DELAY/TSA commands (Sect.
statistic with the COVAR/TSA and
DELAY/TSA commands (Sect. ![]() ). Both COVAR/TSA and
DELAY/TSA are based on a second series of observations which is
used for the model. COVAR/TSA and DELAY/TSA differ in the
method used for the interpolation of the series: the former deploys a
step function (binning) while the latter relies on an analytical
approximation of the autocorrelation function (ACF,
Sect.
). Both COVAR/TSA and
DELAY/TSA are based on a second series of observations which is
used for the model. COVAR/TSA and DELAY/TSA differ in the
method used for the interpolation of the series: the former deploys a
step function (binning) while the latter relies on an analytical
approximation of the autocorrelation function (ACF,
Sect. ![]() ) as a more elaborate approach. Among many other
statistics we mention the one by Lafler & Kinman (1965), phase
dispersion minimization (PDM) also known as the Whittaker & Robinson
statistic (Stellingwerf, 1978), string length (Dvoretsky, 1983), and
statistic introduced by Renson (1983).
) as a more elaborate approach. Among many other
statistics we mention the one by Lafler & Kinman (1965), phase
dispersion minimization (PDM) also known as the Whittaker & Robinson
statistic (Stellingwerf, 1978), string length (Dvoretsky, 1983), and
statistic introduced by Renson (1983).
In the limit of 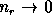 (
(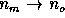 ) the sums of
squares and degrees of freedom converge and so does the variance
) the sums of
squares and degrees of freedom converge and so does the variance 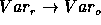 (
( ). Since
). Since 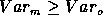 , increasing the number of parameters of a model
, increasing the number of parameters of a model  to
to 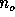 implies a decrease of
implies a decrease of 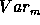 and a corresponding decrease in the
significance of the detection. Therefore, we do not recommend to use
models (e.g. long Fourier series, fine phase binning, string length
and Renson statistics) with more parameters than are really required
for the detection of the feature in question.
and a corresponding decrease in the
significance of the detection. Therefore, we do not recommend to use
models (e.g. long Fourier series, fine phase binning, string length
and Renson statistics) with more parameters than are really required
for the detection of the feature in question.
In the above limits,  and
and  (
( ) become perfectly
correlated. Since all statistics named above except AOV use
) become perfectly
correlated. Since all statistics named above except AOV use 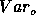 at least implicitly, their probability distribution may, because of
this correlation, differ considerably from what is generally supposed in the
literature (Schwarzenberg-Czerny, 1989). However, the correlation
vanishes in the asymptotic limit
at least implicitly, their probability distribution may, because of
this correlation, differ considerably from what is generally supposed in the
literature (Schwarzenberg-Czerny, 1989). However, the correlation
vanishes in the asymptotic limit 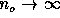 for
for 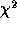 ,
Scargle and Whitteker & Robinson statistics, so that they yield
correct results for sufficiently large data sets. Please note that the
problem of correlation aggravates for observations with high
signal-to-noise ratio,
,
Scargle and Whitteker & Robinson statistics, so that they yield
correct results for sufficiently large data sets. Please note that the
problem of correlation aggravates for observations with high
signal-to-noise ratio,  , as
, as  , so that the statistics mentioned as using these variances
become rather insensitive.
, so that the statistics mentioned as using these variances
become rather insensitive.